|
Key Takeaways
|
|
Orchestration platforms such as Kubernetes and OpenShift help customers reduce costs by enabling on-demand, scalable compute resources. Customers can manually scale out and scale in their Kubernetes compute resources as needed.
Autoscaling is the process of automatically adjusting compute resources to meet a system's performance requirements. As workloads grow, systems require additional resources to sustain performance and handle increasing demand. Conversely, when demand decreases, an automatic scaling service can reduce costs by scaling in unutilized compute resources.
Autoscaling eliminates the need for manual human intervention in the scaling process, reducing the probability of incorrect resource allocation and cutting costs by automatically allocating the exact compute power that is required.
In this post, we will show you how you can use KEDA to easily autoscale your Kubernetes or OpenShift pods based on your own custom in-memory application metrics.
KEDA is a Kubernetes-based, event-driven autoscaler. With KEDA, you can drive the scaling of any container in Kubernetes based on custom application metrics that are external to Kubernetes.
KEDA is introducing a new Kubernetes Custom Resource Definition called ScaledObject. KEDA ScaledObject is used to define how KEDA should scale your application and what the triggers are.
The external ScaledObject can be configured to periodically poll your application (over gRPC protocol) to get the name/value of the custom application metrics that should control the number of pods (replicas) for a specific Kubernetes Deployment/StatefulSet.
This simple example shows how to easily add the related gRPC endpoints to your application to support such custom autoscaling. The gRPC API endpoints that should be added to your application are specified by the externalscaler.proto.
The following example is for building and running the external scaler server that is serving as the gRPC server of your application.
The external-scaler-server is getting the custom metric from the backend external-scaler-web application. Based on the periodic response from the external-scaler-server, KEDA external ScaledObject is automatically scaling the number of worker pods (replicas).
Prerequisites
You will need the following to complete the steps in this post:
The following diagram shows the complete setup that we will walk through in this post:
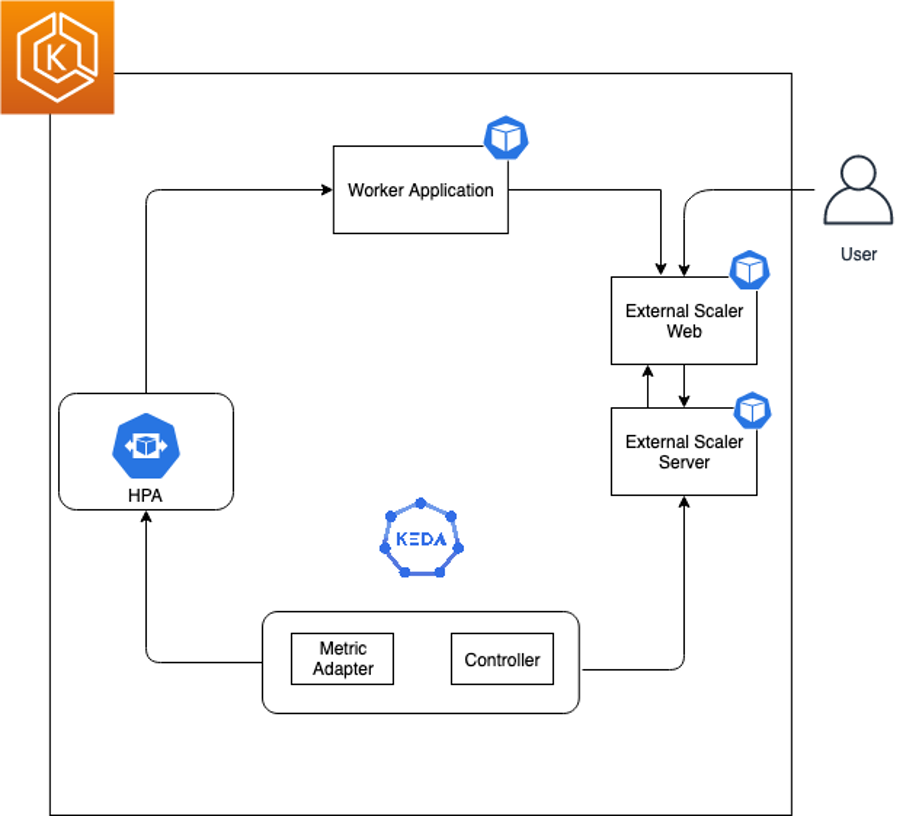
KEDA External Scaler Server setup
Step 1: To get the KEDA External Scaler Server example
- Clone the git repository of external-scaler-samples
git clone https://github.com/kubernetes-zookeeper/external-scaler-samplescd ./external-scaler-samples
Step 2: To build the KEDA External Scaler Server example
This build step is optional and can be skipped. The example is using the following two docker images:
kuberneteszookeeper/external-scaler-webkuberneteszookeeper/external-scaler-server
These two docker images are already stored and available in Docker hub. If you would like to re-build these two docker images, you may execute the following step:
- From the top level external-scaler-samples directory:
Download the gradle 7.4 package and extract it to the gradle folder.wget -O gradle.zip https://services.gradle.org/distributions/gradle-7.4-bin.zip && unzip gradle.zip && /bin/mv gradle-7.4 gradle./gradle/bin/gradle clean docker
This creates the docker images kuberneteszookeeper/external-scaler-web and kuberneteszookeeper/external-scaler-server. The kuberneteszookeeper/external-scaler-web and kuberneteszookeeper/external-scaler-server docker images should be accessible from the k8s cluster.
Step 3: To run the KEDA External Scaler Server example
- To try the external scaler, please run (from the top level external-scaler-samples directory):
./external-scaler-grpc/helm/install_helm.sh./external-scaler-grpc/keda/install_keda.shhelm upgrade --install external-scaler-server ./external-scaler-grpc/helm/external-scaler-server/ --namespace external-scaler-server --create-namespace --values ./external-scaler-grpc/helm/external-scaler-server/values.yaml
AutoScaling in action
The external KEDA ScaledObject is now periodically polling the external-scaler-server (over gRPC protocol) for the name/value of the metric. Based on the value (and the target size for this metric), KEDA is scaling the related worker Deployment/StatefulSet.
In this specific example the metricName is "number_of_jobs" and its targetSize is "4". That is, each worker pod should not run more than "4" application jobs.
For example, when the "number_of_jobs" is "20", KEDA should automatically scale the worker StatefulSet to (20 / 4 =) "5" pods.
In this specific example, the polling interval (pollingInterval) is set to 10 seconds in helm values.yaml.
Let’s put some load on the application by running the following command for creating "20" application jobs:
kubectl exec -n external-scaler-server -it svc/external-scaler-web -- curl -X POST http://external-scaler-web.external-scaler-web.external-scaler-server.svc.cluster.local:8080/external-scaler-web/api/jobs?number_of_jobs=20
The "number_of_jobs" query parameter is controlling how many application jobs should be created.
You may now run the following and watch KEDA auto scaling in action:
kubectl -n external-scaler-server get ScaledObjectkubectl -n external-scaler-server get HorizontalPodAutoScalerkubectl -n external-scaler-server get pods -w
In a different terminal window, you may run the following command to view the gRPC application server log:
kubectl -n external-scaler-server logs -f -l name=external-scaler-server
This example is scaling the number of worker pods (replicas) based on the value of an application metric in real time.
The external-scaler-server pod is running a gRPC server that is responding to the periodic getMetricSpec and getMetrics requests that are generated by the external KEDA ScaledObject.
The docker log of the external-scaler-server pod is showing the response for the periodic getMetricSpec and getMetrics requests that are generated by the external KEDA ScaledObject.
The getMetricSpec response specifies the name of the custom application metric that should control the auto scaling and its target size.
The periodic getMetrics response specifies the value of the custom application metric.
The external KEDA ScaledObject is dividing the returned value of the custom application metric by its target size ( "4" ) - and sets the number of worker pods (replicas) accordingly.
For example, metricValue: "20" and targetSize: "4" will set the worker replicas to 5 ("20" applications jobs require 5 worker pods). Each worker pod should not run more than "4" (targetSize) application jobs.
The worker pods are running each of the application jobs for a random period of time. When each job is completed, the worker is sending a rest call to the external scaler web for deleting the job (reducing the value of the "number_of_jobs" metric by 1).
In different terminal windows you may run the following commands and view the log of any of the worker pods (running the application jobs) or the external scaler web (managing the number of jobs):
kubectl logs -n external-scaler-server -f worker-0kubectl logs -n external-scaler-server -f -l name=external-scaler-web
The targetSize (numberOfJobsPerServer), minimumJobDuration and maximumJobDuration are controlled by the following helm values.yaml:
externalScalerServer: numberOfJobsPerServer: "4" minimumJobDuration: "10" maximumJobDuration: "20"
Clean up
Use the following commands to delete resources created during this post:
helm uninstall external-scaler-server --namespace external-scaler-serverhelm uninstall keda --namespace kedakubectl delete ns external-scaler-serverkubectl delete ns keda
References
- The documentation of the KEDA External Scalers is here: External scalers
- The source code of the external scaler server sample is here: External scaler
- For more information, refer to KEDA.

Ofer Yaniv
Ofer leads the Kubernetes Architecture track within Broadcom AppDev. With over 20 years of experience in designing and developing large-scale applications, he plays a key role in driving innovation and modernization of AppDev solutions through cutting-edge technologies. He is at the forefront of implementing IMS...
Other resources you might be interested in
This Halloween, the Scariest Monsters Are in Your Network
See how network observability can help you identify and tame the zombies, vampires, and werewolves lurking in your network infrastructure.
Your Root Cause Analysis is Flawed by Design
Discover the critical flaw in your troubleshooting approaches. Employ network observability to extend your visibility across the entire service delivery path.
Whose Fault Is It When the Cloud Fails? Does It Matter?
In today's interconnected environments, it is vital to gain visibility into networks you don't own, including internet and cloud provider infrastructures.
The Future of Network Configuration Management is Unified, Not Uncertain
Read this post and discover how Broadcom is breathing new life into the trusted Voyence NCM, making it a core part of its unified observability platform.
Rally Office Hours: October 9, 2025
Discover Rally's new AI-powered Team Health Widget for flow metrics and drill-downs on feature charts. Plus, get updates on WIP limits and future enhancements.
AAI - Navigating the Interface and Refining Data Views
This course introduces you to AAI’s interface and shows you how to navigate efficiently, work with tables, and refine large datasets using search and filter tools.
Rally Office Hours: October 16, 2025
Rally's new AI-driven feature automates artifact breakdown - transforming features into stories or stories into tasks - saving time and ensuring consistency.
What’s New in Network Observability for Fall 2025
Discover how the Fall 2025 release of Network Observability by Broadcom introduces powerful new capabilities, elevating your insights and automation.
Modernizing Monitoring in a Converged IT-OT Landscape
The energy sector is shifting, driven by rapid grid modernization and the convergence of IT and OT networks. Traditional monitoring tools fall short.