As I speak to our automation customers, it's noticeable that more and more are moving to a self-service solution within their scheduling environments. Change management and incident management tools now have APIs, making it unnecessary to do many manual interactions and implementations. Moreover, privilege management tools allow much of the work associated with object creation to be shifted from the scheduling teams directly to application and development teams. It's more efficient to build the design of workload objects in the DevOps toolchain—and it's also less prone to human error. Releasing the scheduling teams from the mundane day-to-day allows them to concentrate on projects that add more value, and it empowers application and development teams and removes implementation bottlenecks.
The challenge
Maintaining site standards and consistency across our environments is a significant challenge as we distribute the responsibility to ever-larger teams. Most companies have mandatory rules or guidelines when implementing changes to their workload systems and objects. These rules are often more stringent in production than in user testing and may be stricter in user testing than in development.
When developers are excited about their new “bright shiny thing” and working to meet tight deadlines, these rules can be easily forgotten or overlooked. Then, some changes need to be made during the promotion to higher-level environments, forcing the changes back into a lower environment for retesting. This causes frustration for developers and it delays their projects, ultimately resulting in added costs for the business.
The mitigation
Runbooks, operating procedures, and guides are often written but seldom read. Moreover, maintaining and distributing content is laborious as environments become more complex and new use cases are established.
To help prevent this, some customers have gone to the length of writing their own “wrapper” scripts for the AutoSys JIL binary. These scripts require a host of standard and best practice checks before allowing changes to be implemented. This wrapper script approach is only a viable solution if all changes are implemented via the AutoSys CLI. However in today's environments, changes often are made via multiple interfaces, such as the AutoSys Web UI (WCC), iXp, CLI, and REST API. Therefore, this is only a partial solution to the enforcement of site standards.
The solution
Embedded Entitlements Manager (EEM) can be used to enforce job naming conventions, but cannot do everything that you may require. AutoSys Workload Automation also has a facility that can be used to check and verify further requirements. This feature is called the JIL Verification Exit (JVE). This is essentially additional code that is called via the application server. The JVE code is executed each time a change is made, regardless of where the change was initiated, including in the CLI, AutoSys Web UI, REST API, iXp, and so on.
Over the years, I have helped multiple customers adopt the JVE. In one case, we enabled a team to retire their wrapper script entirely. The JVE can be used to either modify a JIL attribute value or remove the attribute completely, with a meaningful message provided back to the user.
Here are some of the use cases I have seen:
- Enforcing naming standards
- Limiting the maximum value of attributes, such as n_retry
- Removing attributes that are not supported/used at the customer site, such as service_desk or permission
- Modifying attribute values to meet company standards, for example, owner
- Ensuring a minimum schedule cycle, such as enforcing a minimum five-minute gap between start_mins values
- Preventing unnecessary alarms, for example, to ensure that jobs do not have alarm_if_fail and n_retry enabled
- Preventing unscheduled jobs from being dependent upon themselves
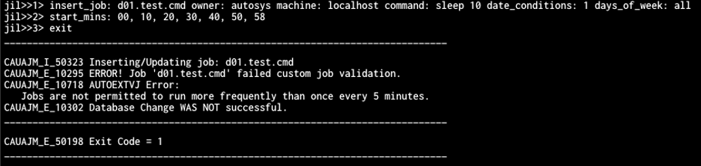
Below is an example of JVE code reading in the specified start_mins attribute. The JVE rejects the change because there is less than a five-minute gap between '00' and '58'.
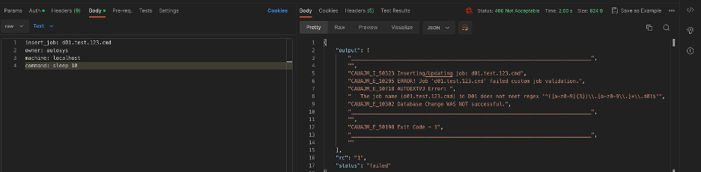
Below is an example of JVE code that standardizes the owner attribute during job creation in the AutoSys Web UI. Instead of rejecting the change and causing the user more work, the JVE amends the owner attribute to “owner@DOMAIN,” and notifies the user in the output.

In the final example, during job creation, the JVE parses the job name to maintain naming standards, and, via the AutoSys REST API, notifies the user that the change has been unsuccessful and why.
Conclusion
As we expand the number of people providing base scheduling rules, we must enforce site standards. However, we must do so in a way that minimizes disruption and effort.
The JVE makes the operational model more efficient, regardless of how schedule changes reach AutoSys. Use it to adjust soft deviations from the standards automatically and, in doing so, prevent the need for the user to edit and resubmit the change manually. Also, use the JVE to maintain your environment's integrity, rejecting hard deviations where necessary.
Watch this demonstration to help you start with the JVE and successfully adapt to the increase in workers who create and maintain scheduling rules.

Jonathan Hiett
Jon is a world-class Solution Architect with decades of experience in the Automation industry spanning the Financial and IT industries. In his role, Jon works with organizations to help define and implement strategies for the execution, management and observability of their workload automation solutions.
Other resources you might be interested in
Rally Office Hours: July 30, 2026
View this session to find out about the new query counter widget, custom list print card updates, dynamic Rally-to-Clarity mapping, and Q3 events.
What’s New in DX NetOps Topology: Summer 2026
See what’s new in DX NetOps topology. Leverage capabilities for expanded multi-vendor discovery, faster triage, custom views, and seamless data exports.
Rally Office Hours: July 23, 2026
Watch the Rally Office Hours from July 23, 2026, featuring updates on custom page migration, governance work rules tips, and upcoming widget releases.
Rally Office Hours: July 16, 2026
This July 16, 2026 Rally Office Hours session highlights a new custom pages substitution variable, custom page migration updates, and community Q&A.
Controlling Flow Telemetry Overhead in Distributed Environments
See how the latest updates to NetOps Flow reduce telemetry overhead and optimize WAN usage. Simplify data extraction and integration with the OData 4 API.
Clarity: Managing Reports
This course is designed for report consumers who need to access, analyze, and manage published reports in Clarity.
Automic Integration Brochure
This brochure serves as your guide to the diverse tools, platforms, and systems that can connect seamlessly with Automic.
Clarity: Configure Reporting Data Sources Using Data Providers
This course explains the data foundation that supports Reporting in Clarity. Learn how Data Providers prepare, organize, secure, and validate reporting data.
Rally Office Hours: July 9, 2026
This session covers the general availability of milestone delivery confidence, troubleshooting for custom views and admin functions, and upcoming webinars.