|
Key Takeaways
|
|
Regardless of which sandwich is their favorite, your customers and end users are highly reliant upon your organization’s network-powered business services. When issues arise that affect the delivery of these services, fast and effective response is a must. The costs of performance issues and downtime can mount by the minute, so sooner is definitely better than later.
While this is easy to understand conceptually, it’s not so easy to make happen in the real world. In pretty much every company, IT and network operations teams struggle to detect potential problems and prevent them from having an impact. The problem is that many teams lack the timely, detailed intelligence they need to track trends, spot potential issues, and address them before services are affected.
Compounding matters is that groups are deluged with raw metrics that lack context, and they don’t have visibility into all the externally owned and managed networks that end users now rely upon, such as those of cloud providers and ISPs.
Instead, teams largely find out about issues when users report them, which poses a couple key problems:
- It is too late. When users report issues, it means the damage has already been done. These issues can have significant, far-ranging business implications, including lost sales and employee productivity for starters. These issues aren’t good for IT and network operations teams’ reputations either. When users have their productivity hindered, they are often frustrated with IT—no matter where the issue arises or who’s ultimately responsible.
- It is too inconsistent and error prone. Fundamentally, depending on user reports is an inconsistent detection strategy. Users may follow up immediately, or they may wait hours or days after the fact. Some users may not alert IT about problems at all. In reporting issues, users may omit or misstate important details. Further, some may not understand or communicate that an issue is critical, while other users may deem even a slight inconvenience to be a top priority.
- It only flags issues. How can you make sure that everything is operating optimally across the board? Do you send out a survey to every user asking about every app? Fundamentally, you need a tool that can confirm system status at any time, not just during an outage.
Given this, it is essential to detect problems before your users become so frustrated that they report them.
Requirement: User experience monitoring
How do your teams start to detect issues before they affect users? You need to employ active, network and web synthetic monitoring that replicates user workflows. Active monitoring enables teams to continuously collect performance data, so they can establish historical information, track trends, and create effective baselines. Through this approach, teams can know that, if synthetic transactions are affected, end users’ transactions will be as well. Here are the key requirements for effective active monitoring approaches:
- Comprehensive coverage. Teams must be able to gain visibility into all the systems and networks users are reliant upon, whether those are internally managed or managed by external third parties, such as ISPs and cloud providers.
- Actionable insights into user experience. NOC staff can’t constantly be buried under massive volumes of alarms. It is vital to minimize alarm noise and ensure alerts are meaningful and actionable. Rather than raw monitoring data, teams need to receive the metrics that are important, revealing specific events that actually have an impact on users. If teams are going to be woken in the middle of the night, it has to be for a good reason.
- Application-aware network visibility and alerting. Various applications have very different characteristics and requirements. For example, voice over Internet Protocol (VoIP) is sensitive to jitter. Web apps are typically reliant upon geographically distributed content delivery networks (CDN), but even something as simple as domain name service (DNS) issues, whether arising locally or upstream, can bring them down. To help teams understand what’s important and what’s not, they need application-aware visibility and alerting that takes these differences into account.
How AppNeta can help
AppNeta by Broadcom offers both active and passive monitoring capabilities that address the key requirements of today’s IT and network operations teams. With the solution, your teams can efficiently and intelligently monitor your modern, dynamic network environments. With its active monitoring capabilities, AppNeta enables teams to replicate a wide range of end-user workflows, including any interactions that go through a web browser.
AppNeta offers the coverage needed to enable fast troubleshooting across all error domains, including remote workers’ wired and Wi-Fi networks, external ISP networks, transit networks, and application service provider environments. With the solution, you can establish continuous coverage of network and application performance from all user locations. This affords you the ability to gather historical information, spot trends to preempt issues, improve thresholds and alerting, and optimize plans and resource allocation. Here are some of the top capabilities and advantages the solution provides.
Track and understand experiences
With the solution’s active monitoring, your teams can gain accurate, actionable intelligence on the user experience. You can identify when any issue arises; it doesn’t even need to be a network issue. Consider the following scenario: Without first providing the necessary training and communications, a security team implements a new control, adding a multi-factor authentication (MFA) step that users must complete before they can access a service.
AppNeta’s active monitoring would immediately detect this change, because its previously established workflow wouldn’t complete correctly. AppNeta could immediately alert based on this failed workflow, and offer details on the step that didn’t complete. It can even provide a screenshot of the window that users would see when the workflow was halted.
Your teams can immediately see what users are seeing, identify the cause of the issue, and take action to remediate.
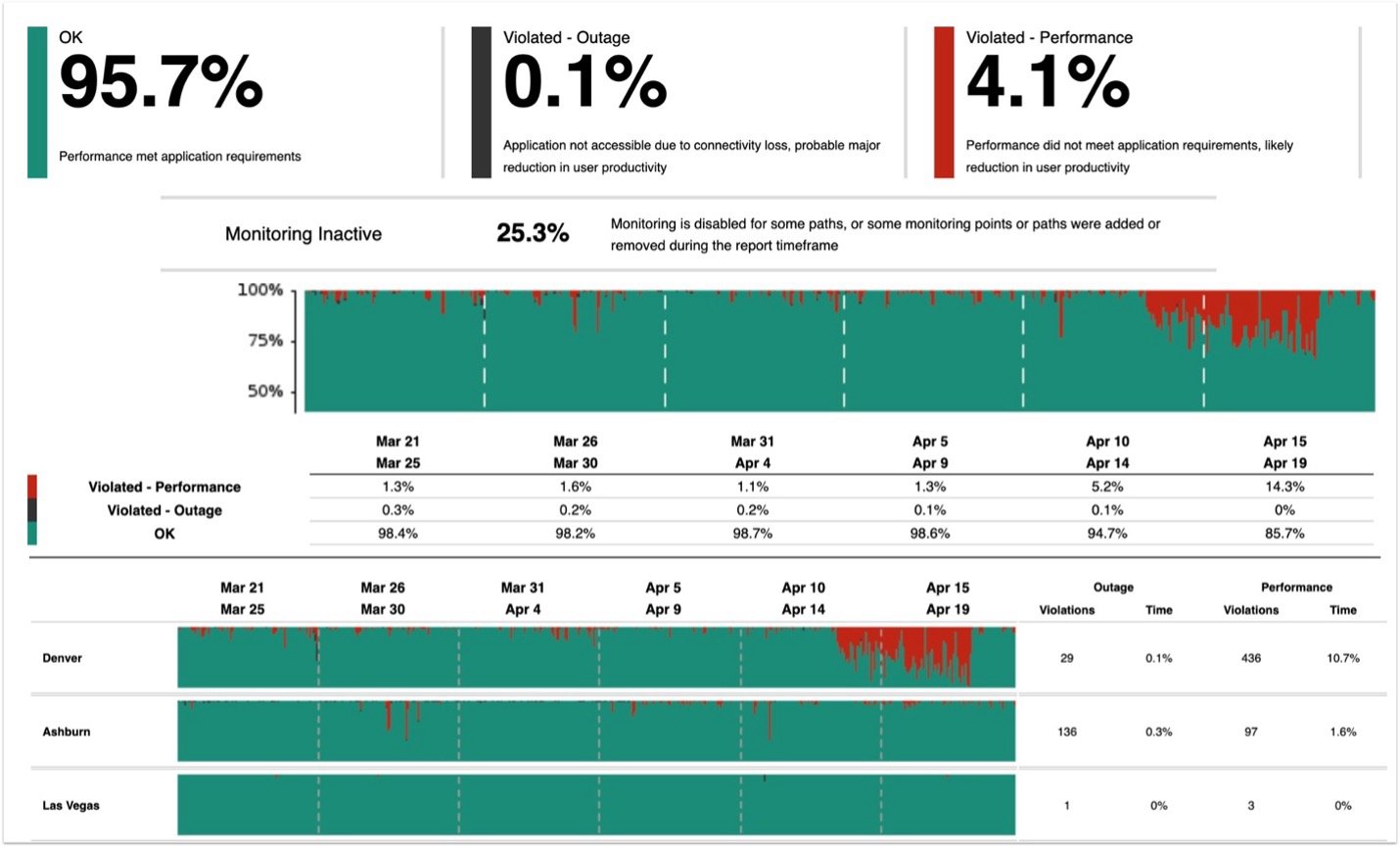
Gain a unified view across all offices, all apps
With AppNeta, you can monitor all your organization’s critical web apps, establishing complete visibility. The solution provides an in-depth look at user experience, whether user connections rely on DNS, CDNs, home Wi-Fi or wired networks, firewalls, load balancers, VPNs, SD-WAN, multi-factor authentication (MFA), or any other technology. If an issue arises that affects users, it will be detected.
Leverage contextual, actionable visibility
AppNeta delivers unified visibility that enables senior leadership to gain insights into overall health, without having to understand the underlying technical details, such as what jitter means. The solution provides reports and dashboards that enable teams to track longer term trends. In addition, it offers automatic diagnostics that can help speed troubleshooting and reduce mean time to resolution (MTTR).
Establish accurate, effective prioritization
With AppNeta, your teams can gain actionable, targeted intelligence through effective thresholds, so you can make better decisions on priority and urgency.
AppNeta delivers the intelligence you need to determine whether to issue an alert, and if so, assign the appropriate severity. For example, a web page may fail to load one time, and load correctly on subsequent occasions. In this case, an alert may not be needed.
Additionally, the solution can help distinguish between a low-level device issue and an issue that has an impact on users and critical services. This can be illustrated by an analogy of a five-lane freeway. If one lane closes at 3:00 am, traffic may see some slight slowing, but you wouldn’t want this issue to trigger an alert that wakes a NOC team up. Staff could very well investigate the issue the next business day, and determine if it is a recurring or potentially worsening problem. On the other hand, four lanes closing at 5:00 pm would absolutely need to trigger a critical alert. With AppNeta, teams can gain the correlated intelligence needed to ensure alarms are triggered at the right times, and with the right level of severity.
Employ intelligent alerting and notifications
With AppNeta, teams can intelligently disseminate alerts. The solution can be used to deliver alerts via email, via SNMP, and, through webhooks, directly into such third-party ticketing systems as Service Now and PagerDuty. The solution can also trigger escalations, so, for example, if an issue persists for 30 minutes, it can automatically send an email to another team.
Track by app and location
With the solution, you can specifically see how a given app, such as Microsoft Teams, is performing from various locations, including your offices, data centers, and remote worker networks. If the service is down, you’ll know if all users are affected. You can also spot if a problem is affecting an entire region, or is a location-specific issue that is just affecting one office.
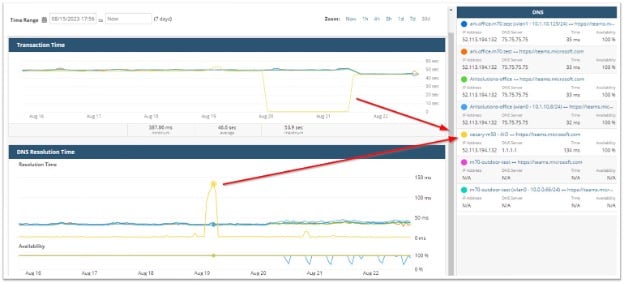
Process: Getting started is easy
Getting started with AppNeta is simple. You start by creating a group, and then define the following aspects:
- Which target URL is to be monitored.
- Where monitoring originates from.
- The workflow. For example, a process could entail instantiating a browser, opening a web page, and submitting credentials to log in.
For more complicated workflows, your teams can use the solution’s recording feature. With this capability, you can record an interaction and use the recording to automatically replicate it as a workflow within AppNeta. Once these workflows are established, AppNeta can begin running them on a continuous basis, repeating them synthetically so it can catch issues, even when users are not working.
How A&I can help
Broadcom partner A&I Solutions is a leading software and services provider with more than 20 years of experience focused on the Broadcom product portfolio. Our team of certified experts know AppNeta inside and out thanks to their many years of experience and training. Our team has the skill and expertise to help with AppNeta deployment planning, automation, best practices, training for incident response, and anything else you may need. Whether you’re short on resources, stuck at an impasse, or just need a trusted expert to offer guidance, we’ve got you covered.
As a full-service partner, we provide complete and total AppNeta software and support to help boost your efforts and ensure uninterrupted business success. Be sure to visit the AppNeta page on the A&I website and get more information on our advanced services, and how we can help you make the most of your AppNeta investments.
Conclusion
With AppNeta, your teams can identify and address issues—before users are affected and before the organization contends with all the negative ramifications of outages and downtime, including lost productivity, lost sales, and so on. To learn more and see a demo of the solution in action, be sure to watch our Small Bytes session, Detecting Problems Early and Before They Affect Everyone.